Data warehouse - keep your data always at hand
Table of Contents

What is data warehouse? #
First of all, I suggest you use your imagination to determine what a data warehouse could be…
Let me narrow your thoughts a little. There we have two words: data and warehouse, let’s consider them one by one:
-
Everything is pretty simple when we talk about data in data warehousing. Any business generates a lot of data from different areas and in different formats. If you want to improve your business and feel more confident in making decisions - you should gather and use this data.
-
I would like to pay more attention to the “warehouse” part. Let’s consider an example of a real, physical warehouse of an aircraft company. Each aircraft produced is the quintessence of engineering thought, constructed using high-quality components and accurate tools. Attention to detail is required at any stage of the development process due to the high safety risks and massive production costs. Beyond this, aircraft is comprised of millions of those components and have to be assembled in the particular shop during the exact time period. To avoid reworks and delays, this complexity has to be managed, especially tools and components that have to be well-structured, counted, and easy to access - this is when the warehouse comes into play.
Now, let’s combine these two definitions.
A data warehouse is a data storage and management system. It consists of current and historical data from various sources and different business areas. Data is structured according to business needs and is usually optimized for business intelligence, while business intelligence helps to make well-grounded decisions based on data analysis.
A data warehouse can contain data from several databases, that store information about sales, hardware products in the physical warehouse, log data, etc., and extracted using the ETL process.
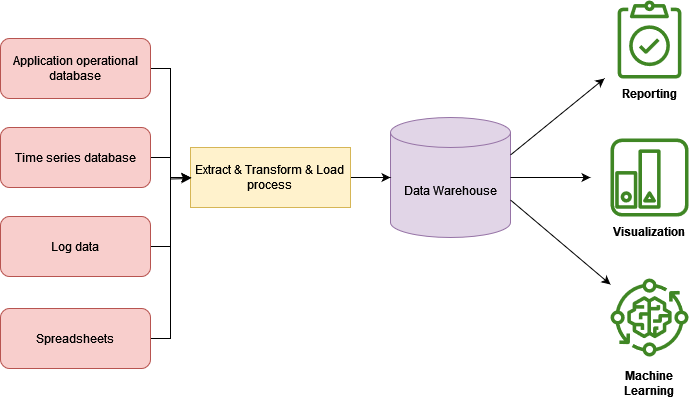
How data warehouse can help your business? #
But wait, all databases fully suit business needs right now while each BI tool has its built-in toolset for getting data from different sources. Why should you care about organizing all your data into a data warehouse?
This question makes perfect sense until a significant increase in the variety of your data sources as well as in need for valuable business intelligence.
A data warehouse gives you a single interface for communication with any of your data sources and to build relations between them. Configured once it allows you to load data to different BI tools without additional investigation of drivers and APIs for particular data sources.
In addition, such a global knowledge base of your business could be a perfect data set for Machine Learning needs.
How to build a data warehouse? #
Data warehouse creation is a very complex process and its whole description is out of the scope of this article. Nevertheless, we can briefly take a look at the common scenario:
- First of all, you should define business objectives. In other words, determine what value do you expect from data warehouse creation.
- If you already know how data from the data warehouse will be used, the initial requirements can be gathered and formulated. For example, you should consider such questions as data updating frequency, data access permissions, types of data sources, etc.
- If you decide to build a data warehouse, one of the most important and underlying things you should consider is architecture. Based on your organization’s needs and resources you can choose between on-premises and cloud-based architectures. Generaly, these solutions have the same pros and cons as when we consider them to store our transactional database.
Cloud-based solution traditionally provides:
- Easier scaling up or down based on demand without the need for significant upfront investment
- More flexibility that makes it possible to deploy new services and technologies rapidly
- Additional services
- Global accessibility
Meanwhile, on-premises solution gives you:
- More customization possibilities
- Direct control over the infrastructure and data security
- More predictable costs in the long term
- As I already mentioned, a data warehouse is mainly optimized for business intelligence so it follows specific data model design patterns. In particular, star schema or snowflake schema are commonly used for data warehousing.
Data warehouse usage example for business intelligence #
I suggest you to try create a sample data warehouse project to see how it can be useful for business intlligence. For the sample project I am going to use cloud-based service by Amazon - Amazon Redshift.
Amazon Redshift for data warehousing #
Redshift is one of the most popular cloud-based data warehouse services, which reap the benefits of cloud computing mentioned above (scalability, flexability, etc.). You can find more information about Redshift on their official website.
How to create data warehouse with Redshift? #
Firstly, follow the official get started guide by Amazon. It is pretty straightforward and I extremely recommend you to pay attention for each accomplished step. At the last part of the guide you’ll be teached how to fill newly created database with data using SQL. Please, do not ignore this part, we will use this queries later for our sample project as well.
Namespaces and workgroups in Amazon Redshift #
Before we continue, we should get familliar with two important concepts in Amazon Redshift: namespaces and workgroups. During the get started guide you created default namespace with a default workgroup associated to this namespace.
Namespace is logical container for database objects and holds tables, workgroups, and other database resources.
Workgroup is a collection of compute resources. The compute-related workgroup groups together compute resources like RPUs, VPC subnet groups, and security groups.
Permissions management #
Since we are going to get access to our workgroup from BI tools, that are out of our Virtual Private Cloud (VPC), we need to create new security group that will accept requests from sources out of our VPC and make our workgroup publicly accessible.
Let’s create a new security group first.
- Search for VPC
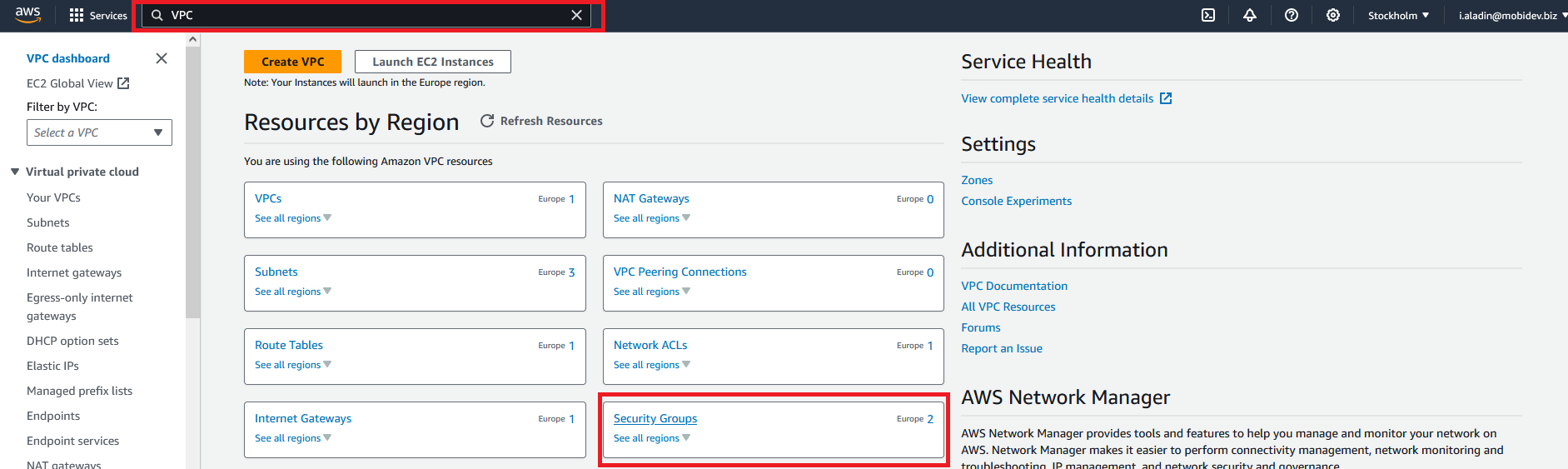
- Open Security Groups
- Press Create security group

- Type security group name and description
- Add inbound rule, where:
- Type: Redshift
- Source: Anywhere-IPv-4
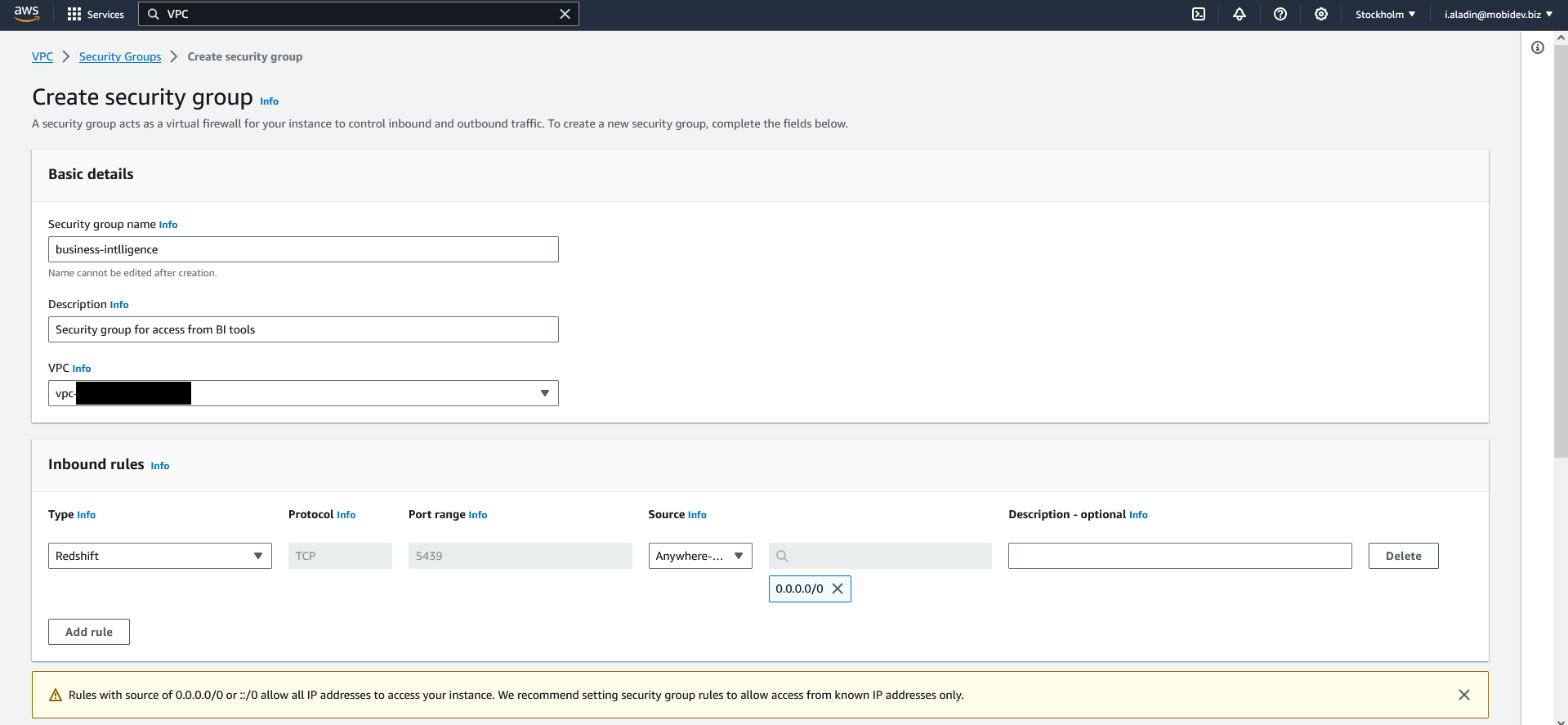
- Click Create security group and wait until it will be created
Once security group is created, we need to create new workgroup using it.
Workgroup creation #
-
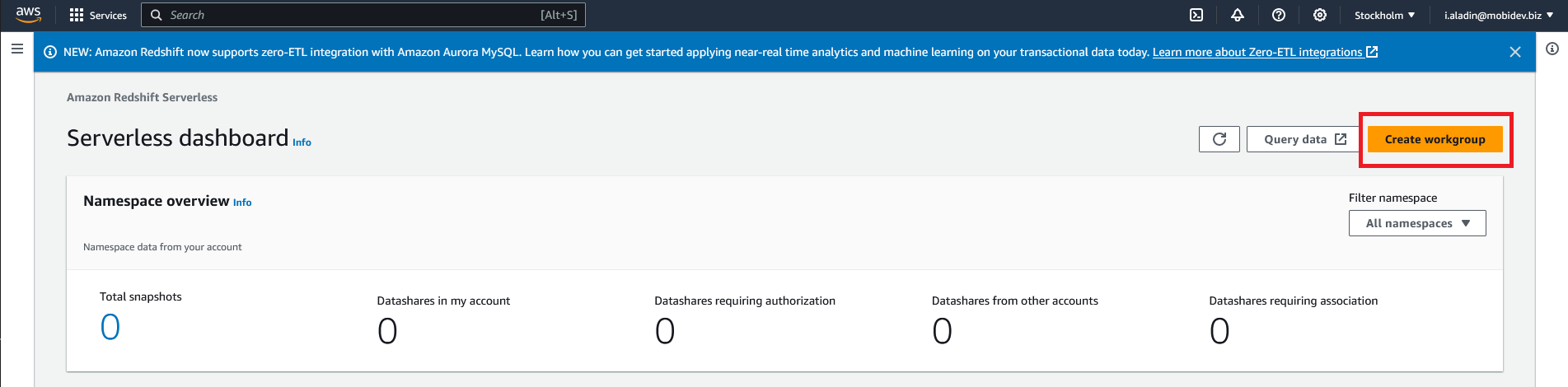
On the Amazon Redshift Serverless dashboard press Create workgroup
-
On the first step of workgroup creation:
- Type workgroup name
- Choose capacity (I chose the smallest possible for sample project)
- Choose newly created security group
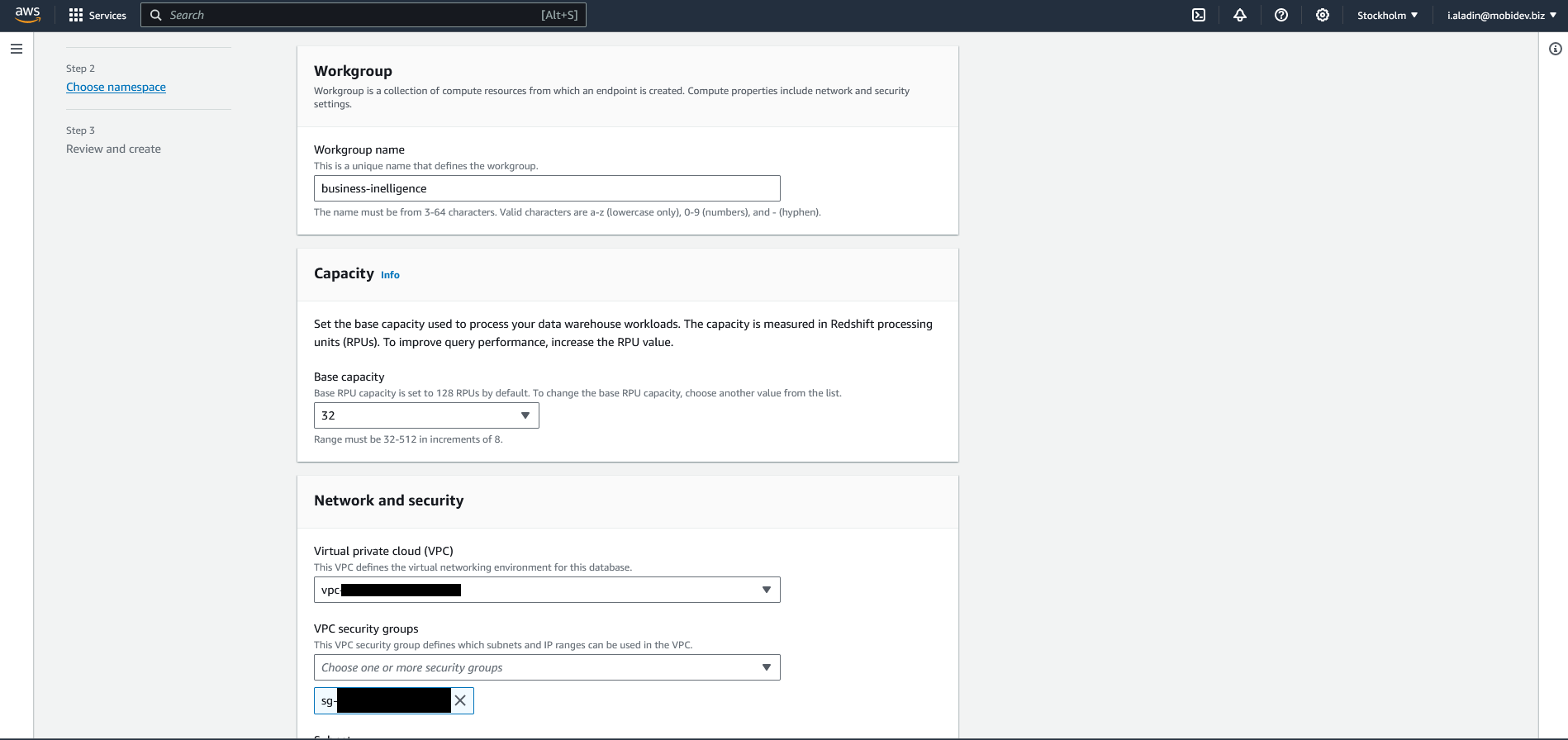
-
On the next step:
- Enter name for the new namespace (I suggest to use the same as for workgroup)
- Check Customize admin user credentials
- Add admin user name and manally add the admin password (important step, we’ll use the credentials during connection to the database)
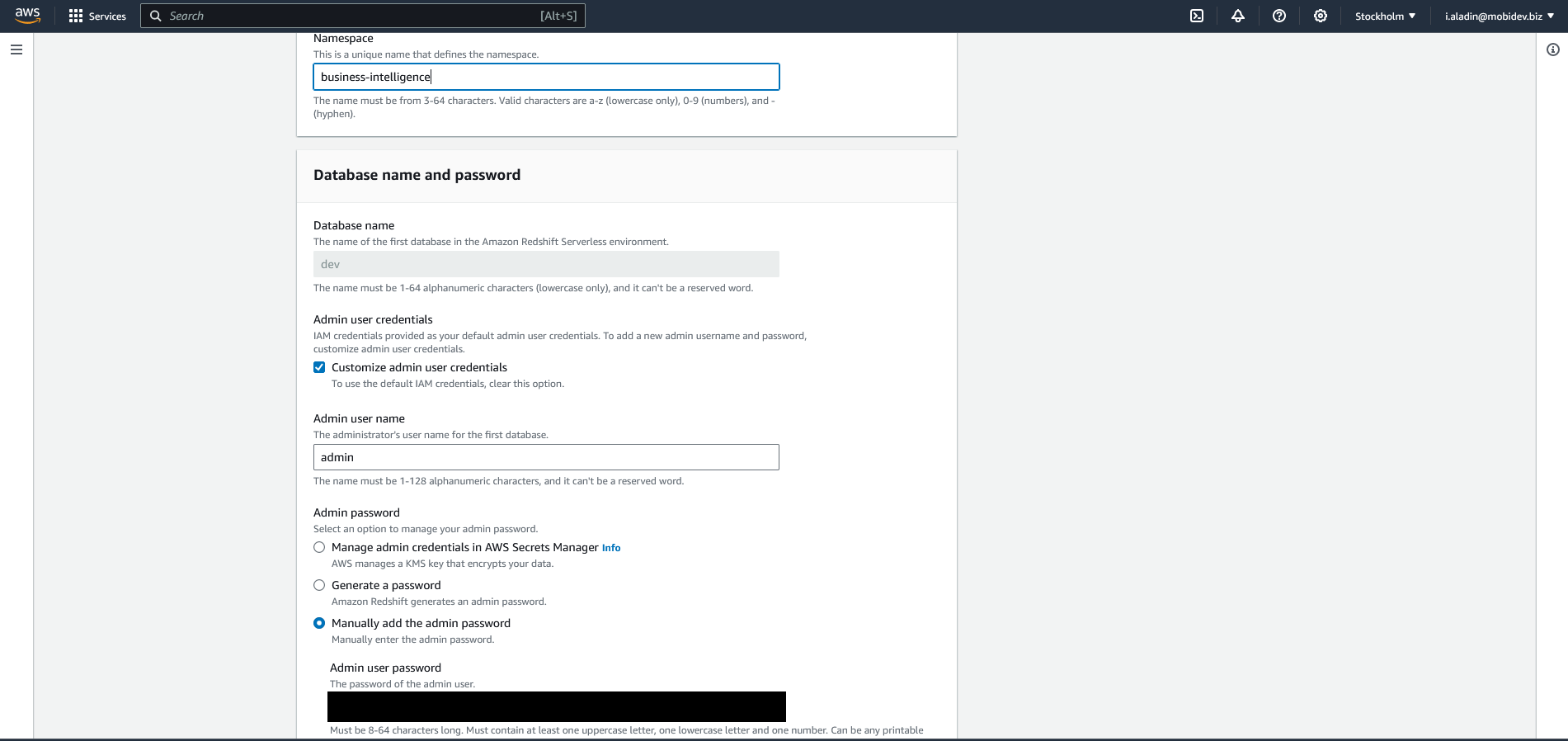
-
Press Create on the final step
As I mentioned earlier, we have to make our workgroup publicly accessible. To do that, in your workgroup under Network and security section change Publicly accessible to On.
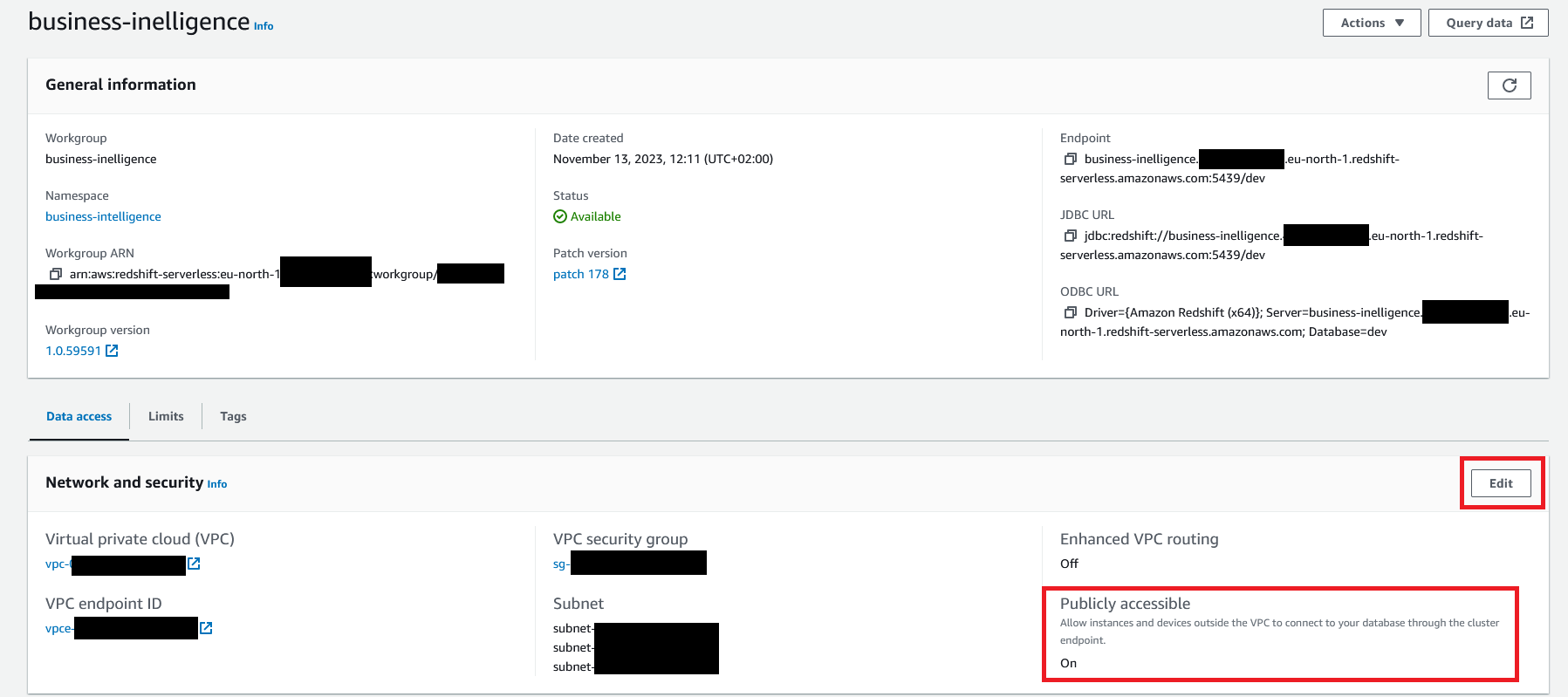
Sample database for new workgroup #
To create a sample database, we have to navigate to the query editor first. On the Amazon Redshift Serverless dashboard press Query data.

Once the query editor is loaded, we need to create a connection with our workgroup:
- On the left pane, choose the newly created workgroup
- Choose Database username and password as an authentication method
- Enter database credentials
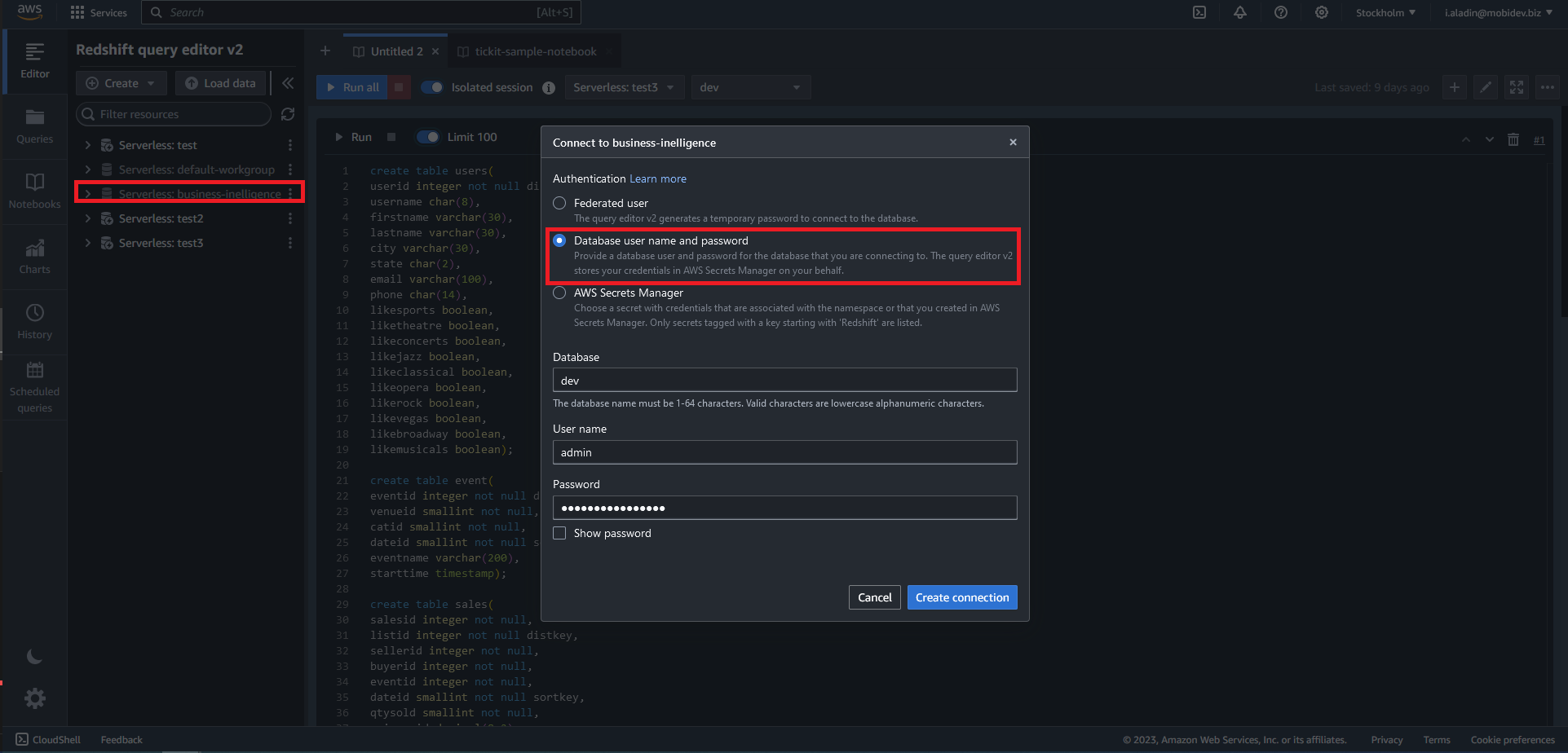
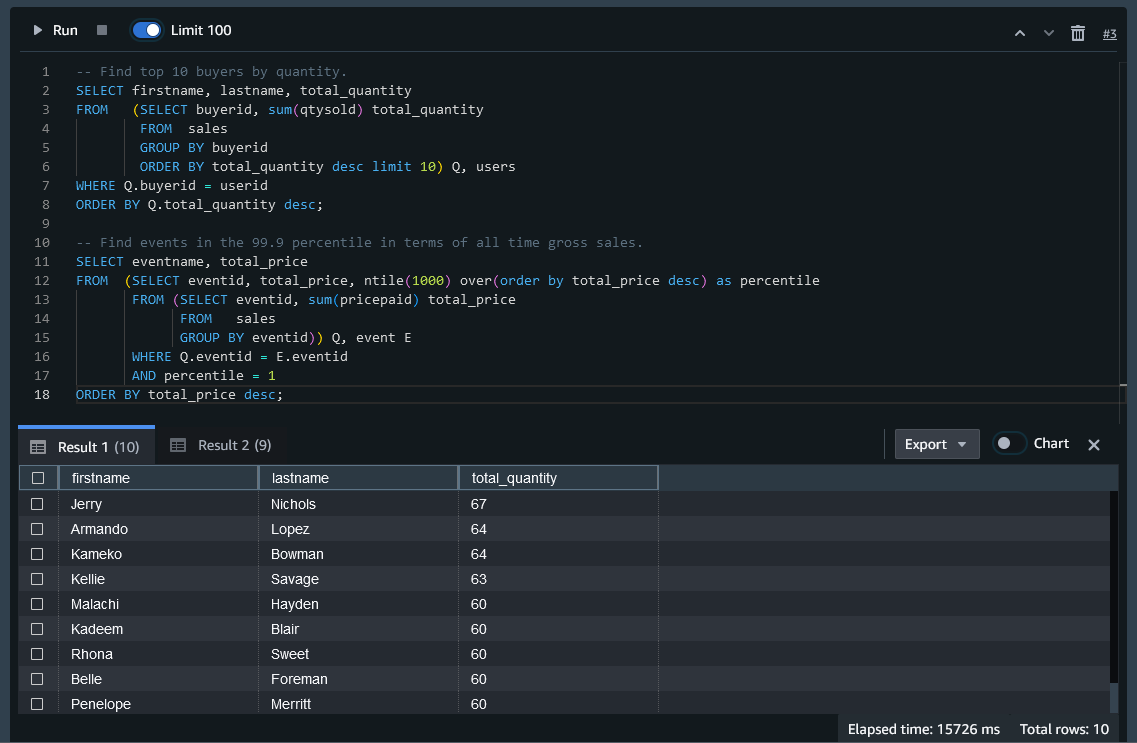
Once the connection is established, we can fill the database in the workgroup with data. If you finished the Get Started guide, you’ll see SQL queries that you used for filling the database with data during accomplishment guide tasks. Let’s reuse these queries to fill the database in our newly created workgroup. The database has the same name dev (default name for the first database in a workgroup) so we just need to run all these queries for our workgroup.
After running queries, you can check the results below. In the third step, we can see the result of querying data.
Connection with BI tools #
Our sample data warehouse is ready and now, we can finally try to establish a connection with it from BI tools.
Let’s consider an example with Power BI first.
Power BI has a built-in toolkit for connection to the Redshift. You can find it in the Get Data menu. The connection tool requires your Redshift Workgroup endpoint (which can be found on the workgroup page), database name (dev in our case), and database credentials.
In addition, the Power BI built-in toolkit provides Advanced options that reap the benefits of query folding. Furthermore, the connector allows the import of data from a database using a native database query (take a look at query folding on native queries as well). It means, that in our case, we can write SQL query during connection establishment to get data we need only (or just copy from query editor) and this query will be executed by Amazon Redshift service directly!
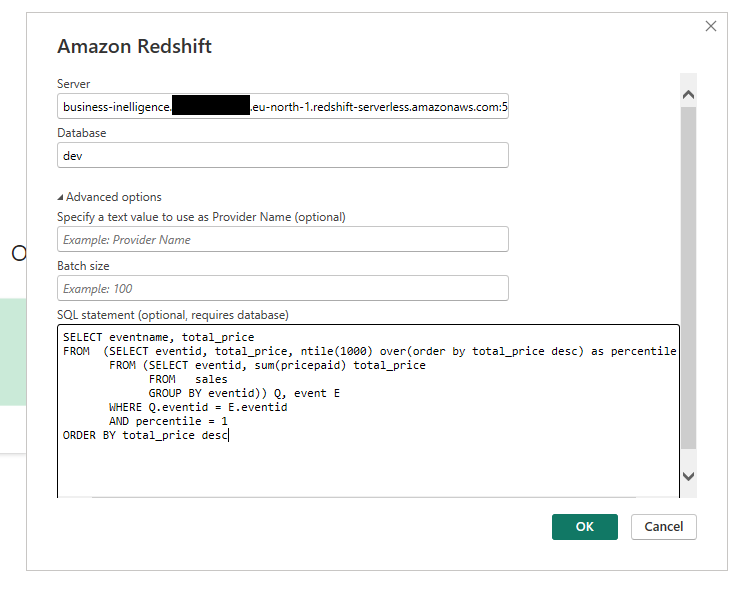
After the connection is ready, you will see the result of the query execution.
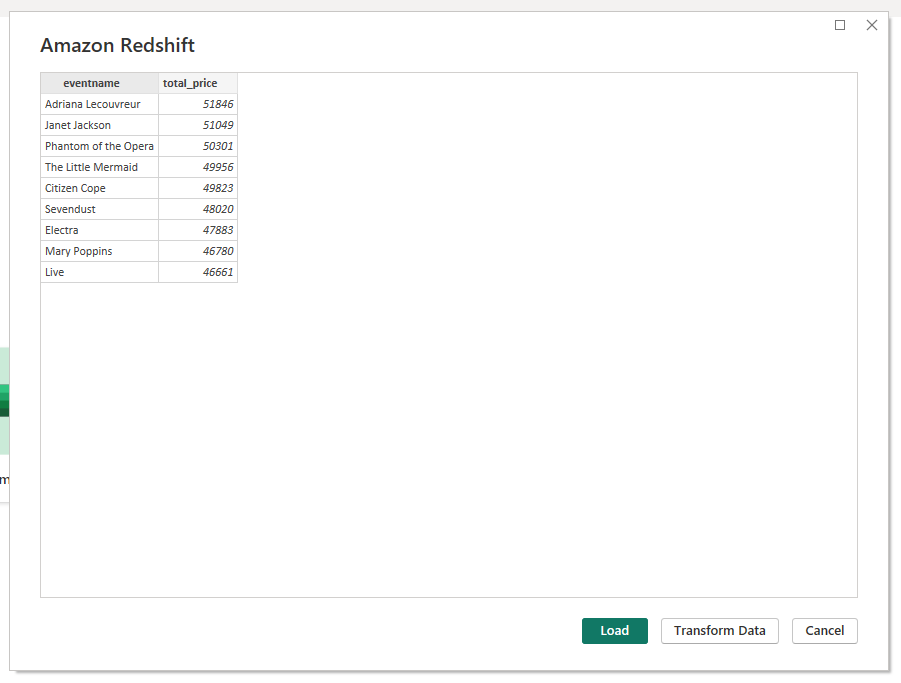
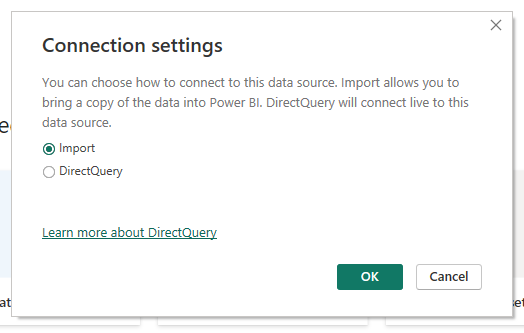
One more benefit of such a connection is that Power BI will give you the opportunity to choose connection settings:
- Import. Power BI will make a copy of your data to work with.
- DirectQuery. Power BI will work with data from your data source directly.
To reveal even more possibilities the data warehouse gives us, you can try to connect to a different BI tool such as Google Looker Studio or Tableau. You will see that all of them have almost the same connection establishment process so you can easily use your data warehouse with different tools.
We are ready to provide expert's help with your product
or build a new one from scratch for you!